前言
reids 没有直接使用C语言传统的字符串表示(以空字符结尾的字符数组)而是构建了一种名为简单动态字符串的抽象类型,并为redis的默认字符串表示,因为C字符串不能满足redis对字符串的安全性、效率以及功能方面的需求
1、SDS 定义
在C语言中,字符串是以'\0'字符结尾(NULL结束符)的字符数组来存储的,通常表达为字符指针的形式(char *)。它不允许字节0出现在字符串中间,因此,它不能用来存储任意的二进制数据。
sds的类型定义
typedef char *sds;
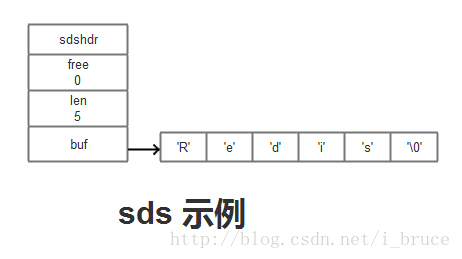
每个sds.h/sdshdr结构表示一个SDS的值
struct sdshdr{
//记录buf数组中已使用的字节的数量
//等于sds所保存字符串的长度
int len;
//记录buf中未使用的数据
int free;
//字符数组,用于保存字符串
}
* free 属性的值为0,表示这个SDS没有分配任何未使用的空间
* len 属性长度为5,表示这个SDS保存一个五字节长的字符串
* buf 属性是一个char类型的数组,数组的前5个字节分别保存了'R','e','d','i','s'五个字符,而最后一个字节则保存了空字符串'\0'
肯定有人感到困惑了,竟然sds就等同于char *?
sds和传统的C语言字符串保持类型兼容,因此它们的类型定义是一样的,都是char *,在有些情况下,需要传入一个C语言字符串的地方,也确实可以传入一个sds。
但是sds和char *并不等同,sds是Binary Safe的,它可以存储任意二进制数据,不能像C语言字符串那样以字符'\0'来标识字符串的结束,因此它必然有个长度字段,这个字段在header中
sds的header结构
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
SDS一共有5种类型的header。目的是节省内存。
一个SDS字符串的完整结构,由在内存地址上前后相邻的两部分组成:
- 一个header。通常包含字符串的长度(len)、最大容量(alloc)和flags。sdshdr5有所不同。
- 一个字符数组。这个字符数组的长度等于最大容量+1。真正有效的字符串数据,其长度通常小于最大容量。在真正的字符串数据之后,是空余未用的字节(一般以字节0填充),允许在不重新分配内存的前提下让字符串数据向后做有限的扩展。在真正的字符串数据之后,还有一个NULL结束符,即ASCII码为0的'\0'字符。这是为了和传统C字符串兼容。之所以字符数组的长度比最大容量多1个字节,就是为了在字符串长度达到最大容量时仍然有1个字节存放NULL结束符。
除了sdshdr5之外,其它4个header的结构都包含3个字段:
- len: 表示字符串的真正长度(不包含NULL结束符在内)。
- alloc: 表示字符串的最大容量(不包含最后多余的那个字节)。
- flags: 总是占用一个字节。其中的最低3个bit用来表示header的类型。
在各个header的类型定义中,还有几个需要我们注意的地方:
- 在各个header的定义中使用了__attribute__ ((packed)),是为了让编译器以紧凑模式来分配内存。如果没有这个属性,编译器可能会为struct的字段做优化对齐,在其中填充空字节。那样的话,就不能保证header和sds的数据部分紧紧前后相邻,也不能按照固定向低地址方向偏移1个字节的方式来获取flags字段了。
- 在各个header的定义中最后有一个char buf[]。我们注意到这是一个没有指明长度的字符数组,这是C语言中定义字符数组的一种特殊写法,称为柔性数组(flexible array member),只能定义在一个结构体的最后一个字段上。它在这里只是起到一个标记的作用,表示在flags字段后面就是一个字符数组,或者说,它指明了紧跟在flags字段后面的这个字符数组在结构体中的偏移位置。而程序在为header分配的内存的时候,它并不占用内存空间。如果计算sizeof(struct sdshdr16)的值,那么结果是5个字节,其中没有buf字段。
- sdshdr5与其它几个header结构不同,它不包含alloc字段,而长度使用flags的高5位来存储。因此,它不能为字符串分配空余空间。如果字符串需要动态增长,那么它就必然要重新分配内存才行。所以说,这种类型的sds字符串更适合存储静态的短字符串(长度小于32)。
至此,我们非常清楚地看到了:sds字符串的header,其实隐藏在真正的字符串数据的前面(低地址方向)。这样的一个定义,有如下几个好处:
- header和数据相邻,而不用分成两块内存空间来单独分配。这有利于减少内存碎片,提高存储效率(memory efficiency)。
- 虽然header有多个类型,但sds可以用统一的char *来表达。且它与传统的C语言字符串保持类型兼容。如果一个sds里面存储的是可打印字符串,那么我们可以直接把它传给C函数,比如使用strcmp比较字符串大小,或者使用printf进行打印。
弄清了sds的数据结构,它的具体操作函数就比较好理解了。
sds的一些基础函数
- sdslen(const sds s): 获取sds字符串长度。
- sdssetlen(sds s, size_t newlen): 设置sds字符串长度。
- sdsinclen(sds s, size_t inc): 增加sds字符串长度。
- sdsalloc(const sds s): 获取sds字符串容量。
- sdssetalloc(sds s, size_t newlen): 设置sds字符串容量。
- sdsavail(const sds s): 获取sds字符串空余空间(即alloc - len)。
- sdsHdrSize(char type): 根据header类型得到header大小。
- sdsReqType(size_t string_size): 根据字符串数据长度计算所需要的header类型。
二、SDS 数组动态分配策略
header信息中的定义这么多字段,其中一个很重要的作用就是实现对字符串的灵活操作并且尽量减少内存重新分配和回收操作。
redis的内存分配策略如下
- 当SDS的len属性长度小于1MB时,redis会分配和len相同长度的free空间。至于为什么这样分配呢,上次用了len长度的空间,那么下次程序可能也会用len长度的空间,所以redis就为你预分配这么多的空间。
- 但是当SDS的len属性长度大于1MB时,程序将多分配1M的未使用空间。这个时候我在根据这种惯性预测来分配的话就有点得不偿失了。所以redis是将1MB设为一个风险值,没过风险值你用多少我就给你多少,过了的话那这个风险值就是我能给你临界值
reids的内存回收策略如下
- redis的内存回收采用惰性回收,即你把字符串变短了,那么多余的内存空间我先不还给操作系统,先留着,万一马上又要被使用呢。短暂的持有资源,既可以充分利用资源,也可以不浪费资源。这是一种很优秀的思想。
综上所述,redis实现的高性能字符串的结果就把N次字符串操作必会发生N次内存重新分配变为人品最差时最多发生N次重新分配。
/* Enlarge the free space at the end of the sds string so that the caller
* is sure that after calling this function can overwrite up to addlen
* bytes after the end of the string, plus one more byte for nul term.
*
* Note: this does not change the *length* of the sds string as returned
* by sdslen(), but only the free buffer space we have. */
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
size_t avail = sdsavail(s);
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
/* Return ASAP if there is enough space left. */
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
newlen = (len+addlen);
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
type = sdsReqType(newlen);
/* Don't use type 5: the user is appending to the string and type 5 is
* not able to remember empty space, so sdsMakeRoomFor() must be called
* at every appending operation. */
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
hdrlen = sdsHdrSize(type);
if (oldtype==type) {
newsh = s_realloc(sh, hdrlen+newlen+1);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
/* Since the header size changes, need to move the string forward,
* and can't use realloc */
newsh = s_malloc(hdrlen+newlen+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
sdssetalloc(s, newlen);
return s;
}
/* Reallocate the sds string so that it has no free space at the end. The
* contained string remains not altered, but next concatenation operations
* will require a reallocation.
*
* After the call, the passed sds string is no longer valid and all the
* references must be substituted with the new pointer returned by the call. */
sds sdsRemoveFreeSpace(sds s) {
void *sh, *newsh;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
size_t len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
type = sdsReqType(len);
hdrlen = sdsHdrSize(type);
if (oldtype==type) {
newsh = s_realloc(sh, hdrlen+len+1);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
newsh = s_malloc(hdrlen+len+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
sdssetalloc(s, len);
return s;
}
三、SDS的特点
sds正是在Redis中被广泛使用的字符串结构,它的全称是Simple Dynamic String。与其它语言环境中出现的字符串相比,它具有如下显著的特点:
- 可动态扩展内存。SDS表示的字符串其内容可以修改,也可以追加。在很多语言中字符串会分为mutable和immutable两种,SDS属于mutable类型的。
- 二进制安全(Binary Safe)。sds能存储任意二进制数据。
- 与传统的C语言字符串类型兼容。
- 预分配空间,可以懒惰释放,在内存紧张的时候也可以缩减不需要的内存
- 常数复杂度获取字符串长度
- 杜绝缓冲区溢出,边界检查
四、浅谈SDS与string的关系
127.0.0.1:6379> set test test OK 127.0.0.1:6379> append test " test" (integer) 9 127.0.0.1:6379> get test "test test" 127.0.0.1:6379> setbit test 36 1 (integer) 0 127.0.0.1:6379> get test "test(test" 127.0.0.1:6379> getrange test -5 -1 "(test"
- append操作使用SDS的sdscatlen来实现。
- setbit和getrange都是先根据key取到整个sds字符串,然后再从字符串选取或修改指定的部分。由于SDS就是一个字符数组,所以对它的某一部分进行操作似乎都比较简单。
但是,string除了支持这些操作之外,当它存储的值是个数字的时候,它还支持incr、decr等操作。它的内部存储不是SDS,这种情况下,setbit和getrange的实现也会有所不同。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对脚本之家的支持。
参考文章
- http://blog.csdn.net/xiejingfa/article/details/50972592
- http://blog.csdn.net/acceptedxukai/article/details/17482611
- https://segmentfault.com/a/1190000003984537
发表评论 取消回复