今天来学习alsotang的爬虫教程,跟着把CNode简单地爬一遍。
建立项目craelr-demo
我们首先建立一个Express项目,然后将app.js的文件内容全部删除,因为我们暂时不需要在Web端展示内容。当然我们也可以在空文件夹下直接 npm install express来使用我们需要的Express功能。
目标网站分析
如图,这是CNode首页一部分div标签,我们就是通过这一系列的id、class来定位我们需要的信息。
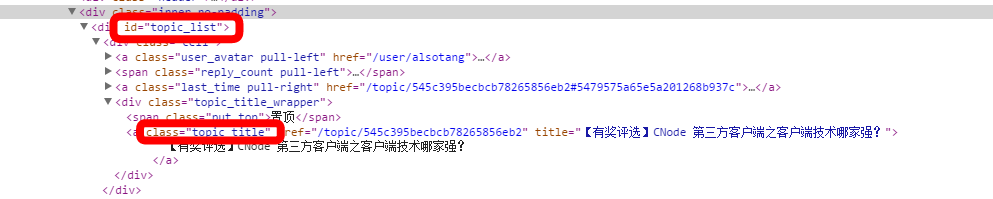
使用superagent获取源数据
superagent就是ajax API来使用的Http库,它的使用方法与jQuery差不多,我们通过它发起get请求,在回调函数中输出结果。
var express = require('express');
var url = require('url'); //解析操作url
var superagent = require('superagent'); //这三个外部依赖不要忘记npm install
var cheerio = require('cheerio');
var eventproxy = require('eventproxy');
var targetUrl = 'https://cnodejs.org/';
superagent.get(targetUrl)
.end(function (err, res) {
console.log(res);
});
它的res结果为一个包含目标url信息的对象,网站内容主要在其text(string)里。
使用cheerio解析
cheerio充当服务器端的jQuery功能,我们先使用它的.load()来载入HTML,再通过CSS selector来筛选元素。
var $ = cheerio.load(res.text);
//通过CSS selector来筛选数据
$('#topic_list .topic_title').each(function (idx, element) {
console.log(element);
});
其结果为一个个对象,调用 .each(function(index, element))函数来遍历每一个对象,返回的是HTML DOM Elements。

输出 console.log($element.attr('title'));的结果为 广州 2014年12月06日 NodeParty 之 UC 场
之类的标题,输出 console.log($element.attr('href'));的结果为 /topic/545c395becbcb78265856eb2之类的url。再用NodeJS1的url.resolve()函数来补全完整的url。
superagent.get(tUrl)
.end(function (err, res) {
if (err) {
return console.error(err);
}
var topicUrls = [];
var $ = cheerio.load(res.text);
// 获取首页所有的链接
$('#topic_list .topic_title').each(function (idx, element) {
var $element = $(element);
var href = url.resolve(tUrl, $element.attr('href'));
console.log(href);
//topicUrls.push(href);
});
});
使用eventproxy来并发抓取每个主题的内容
教程上展示了深度嵌套(串行)方法和计数器方法的例子,eventproxy就是使用事件(并行)方法来解决这个问题。当所有的抓取完成后,eventproxy接收到事件消息自动帮你调用处理函数。
//第一步:得到一个 eventproxy 的实例
var ep = new eventproxy();
//第二步:定义监听事件的回调函数。
//after方法为重复监听
//params: eventname(String) 事件名,times(Number) 监听次数, callback 回调函数
ep.after('topic_html', topicUrls.length, function(topics){
// topics 是个数组,包含了 40 次 ep.emit('topic_html', pair) 中的那 40 个 pair
//.map
topics = topics.map(function(topicPair){
//use cheerio
var topicUrl = topicPair[0];
var topicHtml = topicPair[1];
var $ = cheerio.load(topicHtml);
return ({
title: $('.topic_full_title').text().trim(),
href: topicUrl,
comment1: $('.reply_content').eq(0).text().trim()
});
});
//outcome
console.log('outcome:');
console.log(topics);
});
//第三步:确定放出事件消息的
topicUrls.forEach(function (topicUrl) {
superagent.get(topicUrl)
.end(function (err, res) {
console.log('fetch ' + topicUrl + ' successful');
ep.emit('topic_html', [topicUrl, res.text]);
});
});
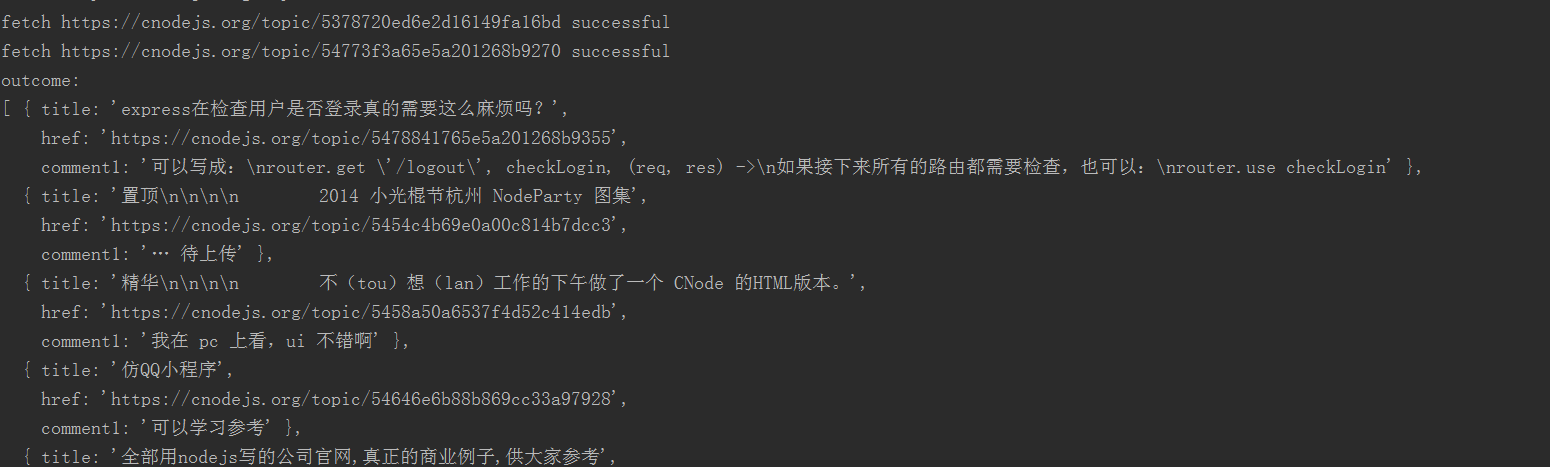
结果如下
扩展练习(挑战)
获取留言用户名和积分
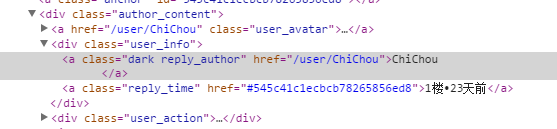
在文章页面的源码找到评论的用户class名,classname为reply_author。console.log第一个元素 $('.reply_author').get(0)可以看到,我们需要获取东西都在这里头。
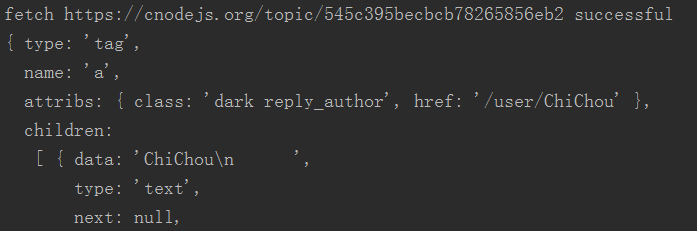
首先,我们先对一篇文章进行抓取,一次性把需要的都得到即可。
var userHref = url.resolve(tUrl, $('.reply_author').get(0).attribs.href);
console.log(userHref);
console.log($('.reply_author').get(0).children[0].data);
我们可以通过https://cnodejs.org/user/username抓取积分信息
$('.reply_author').each(function (idx, element) {
var $element = $(element);
console.log($element.attr('href'));
});
在用户信息页面 $('.big').text().trim()即为积分信息。
使用cheerio的函数.get(0)为获取第一个元素。
var userHref = url.resolve(tUrl, $('.reply_author').get(0).attribs.href);
console.log(userHref);
这只是对于单个文章的抓取,对于40个还有需要修改的地方。
发表评论 取消回复